
淏荃君分享:IIS日志中搜索引擎蜘蛛名称代码及爬寻返回代码

在SEOer做网站的诊断分析时,想了解一个网站的目前状态,首先要学会的就是如何查看IIS日志,因为网站的一些搜索引擎蜘蛛爬寻状况和访问IP的来源都会记录在IIS日志中,所以IIS日志对每个SEOer或网站管理者非常的重要,淏荃君觉得要想准确的解读这些网站日志,我们首先就要先明白IIS日志中搜索引擎蜘蛛名称代码及爬寻返回代码分别是什么?又代表着什么意思?
百度蜘蛛:BaiduSpider
谷歌蜘蛛:Googlebot
谷歌专门抓取图片的蜘蛛:Googlebot-Image
谷歌广告联盟代码的蜘蛛:Mediapartners-Google
360搜索蜘蛛:360Spider
搜狗蜘蛛:SogouNewsSpider
搜狗蜘蛛还包括如下这些:Sogouwebspider、Sogouinstspider、Sogouspider2、Sogoublog、SogouNewsSpider、SogouOrionspider(参考一些网站的robots文件,搜狗蜘蛛名称可以用Sogou概括)
SOSO蜘蛛:Sosospider
雅虎蜘蛛:YahooSlurp
雅虎中国蜘蛛:Yahoo!SlurpChina
雅虎广告蜘蛛:Yahoo!-AdCrawler
网易有道蜘蛛:YoudaoBot,YodaoBot
MSN蜘蛛:msnbot,msnbot-media
必应蜘蛛:bingbot
Alexa蜘蛛:ia_archiver
即刻蜘蛛:JikeSpider
一搜蜘蛛:YisouSpider
宜搜蜘蛛:EasouSpider
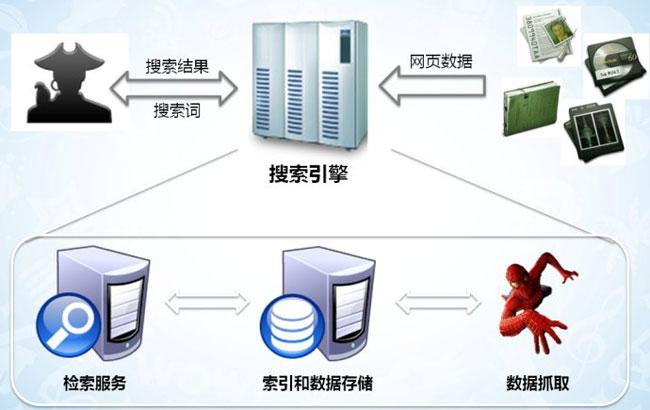
搜索引擎工作原理
1xx(临时响应)表示临时响应并需要请求者继续执行操作的状态代码。
100(继续)请求者应当继续提出请求。服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
101(切换协议)请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx(成功)表示成功处理了请求的状态代码。
200(成功)服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。
201(已创建)请求成功并且服务器创建了新的资源。
202(已接受)服务器已接受请求,但尚未处理。
203(非授权信息)服务器已成功处理了请求,但返回的信息可能来自另一来源。
204(无内容)服务器成功处理了请求,但没有返回任何内容。
205(重置内容)服务器成功处理了请求,但没有返回任何内容。
206(部分内容)服务器成功处理了部分GET请求。
3xx(重定向)表示要完成请求,需要进一步操作。通常,这些状态代码用来重定向。
300(多种选择)针对请求,服务器可执行多种操作。服务器可根据请求者(useragent)选择一项操作,或提供操作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。服务器返回此响应(对GET或HEAD请求的响应)时,会自动将请求者转到新位置。
302(临时移动)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
303(查看其他位置)请求者应当对不同的位置使用单独的GET请求来检索响应时,服务器返回此代码。
304(未修改)自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。
305(使用代理)请求者只能使用代理访问请求的网页。如果服务器返回此响应,还表示请求者应使用代理。
307(临时重定向)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
4xx(请求错误)这些状态代码表示请求可能出错,妨碍了服务器的处理。
400(错误请求)服务器不理解请求的语法。
401(未授权)请求要求身份验证。对于需要登录的网页,服务器可能返回此响应。
403(禁止)服务器拒绝请求。
404(未找到)服务器找不到请求的网页。
405(方法禁用)禁用请求中指定的方法。
406(不接受)无法使用请求的内容特性响应请求的网页。
407(需要代理授权)此状态代码与401(未授权)类似,但指定请求者应当授权使用代理。
408(请求超时)服务器等候请求时发生超时。
409(冲突)服务器在完成请求时发生冲突。服务器必须在响应中包含有关冲突的信息。
410(已删除)如果请求的资源已永久删除,服务器就会返回此响应。
411(需要有效长度)服务器不接受不含有效内容长度标头字段的请求。
412(未满足前提条件)服务器未满足请求者在请求中设置的其中一个前提条件。
413(请求实体过大)服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414(请求的URI过长)请求的URI(通常为网址)过长,服务器无法处理。
415(不支持的媒体类型)请求的格式不受请求页面的支持。
416(请求范围不符合要求)如果页面无法提供请求的范围,则服务器会返回此状态代码。
417(未满足期望值)服务器未满足”期望”请求标头字段的要求。
5xx(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求出错。
500(服务器内部错误)服务器遇到错误,无法完成请求。
501(尚未实施)服务器不具备完成请求的功能。例如,服务器无法识别请求方法时可能会返回此代码。
502(错误网关)服务器作为网关或代理,从上游服务器收到无效响应。
503(服务不可用)服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态。
504(网关超时)服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505(HTTP版本不受支持)服务器不支持请求中所用的HTTP协议版本。
分析解读IIS网站日志中的“2013-10-2600:09:12W3SVC.28.163.196GET/index.html–80–61.135.168.39Baiduspider+(+
)”是什么意思?

1、2008-08-1900:09:12代表搜索引擎蜘蛛爬行的日期与时间
2、W3SVC代表网站日志所在的文件夹
3、115.28.163.196就是搜索引擎蜘蛛访问的网站ip(比如:太原SEO研究中心博客的ip是115.28.163.196)
4、代码中的/index.html就代表搜索引擎蜘蛛防问的网页
5、61.135.168.39Baiduspider代表,百度搜索引擎蜘蛛的ip是61.135.168.39
6、
常见问题解答网页
7、代码中的200就代表搜索引擎蜘蛛爬行后返回HTTP状态代码,通过上面的搜索引擎爬寻返回代码可以了解蜘蛛爬行后的反映。
8、关于蜘蛛在IIS里的的状态行为分析:
根据淏荃君对太原SEO研究中心博客iis日志一段时间的观察,虽然暂时还没有足够的证据,但是基本上可以肯定在IIS中,如果蜘蛛后面的号码出现,那么网站中的这个单页面就会在搜索引擎中消失了。太原SEO研究中心博客上被K的页都面后面写着,不知道大家是否认同这个看法,当然,淏荃君说这个也并不是绝对的,因为我也有一个页面后面显示着但是在搜索引擎中依旧可以找到。这也说明着问题,但大多行为的网页就已经没有了。
淏荃君认为,抓取状态成的可能是不正常的抓取,正常的抓取是成功标志,当变成了的状态时说明搜索引擎在抓取这个页面的时候出现了错误,没有正常的进行常规抓取;对于百度来说,百度很可能是已经不再把这些页面抓进主索引库,而是放进了“百度沙盒”里进行考察,至于考察多久,就看你如何改进了。
所以淏荃君觉得蜘蛛的行为可以被解释为清除数据。