
搜索引擎页面抓取流程
搜索引擎对网页的抓取动作是通过网络爬虫(蜘蛛)在整个互联网平台上进行信息的采集和抓取,这是搜索引擎最基本的动作。
搜索引擎蜘蛛/机器人采集的力度直接决定了搜索引擎前端检索器可提供的信息覆盖面,同时影响反馈给用户检索查询信息的质量。所以,搜索引擎本身在不断设法提高其数据采行抓取及分析的能力。
搜索引擎页面抓取流程
在整个互联网中,URL是每个页面的入口地址,同时搜索引擎蜘蛛程序也是通过URL来抓取网站页面的。
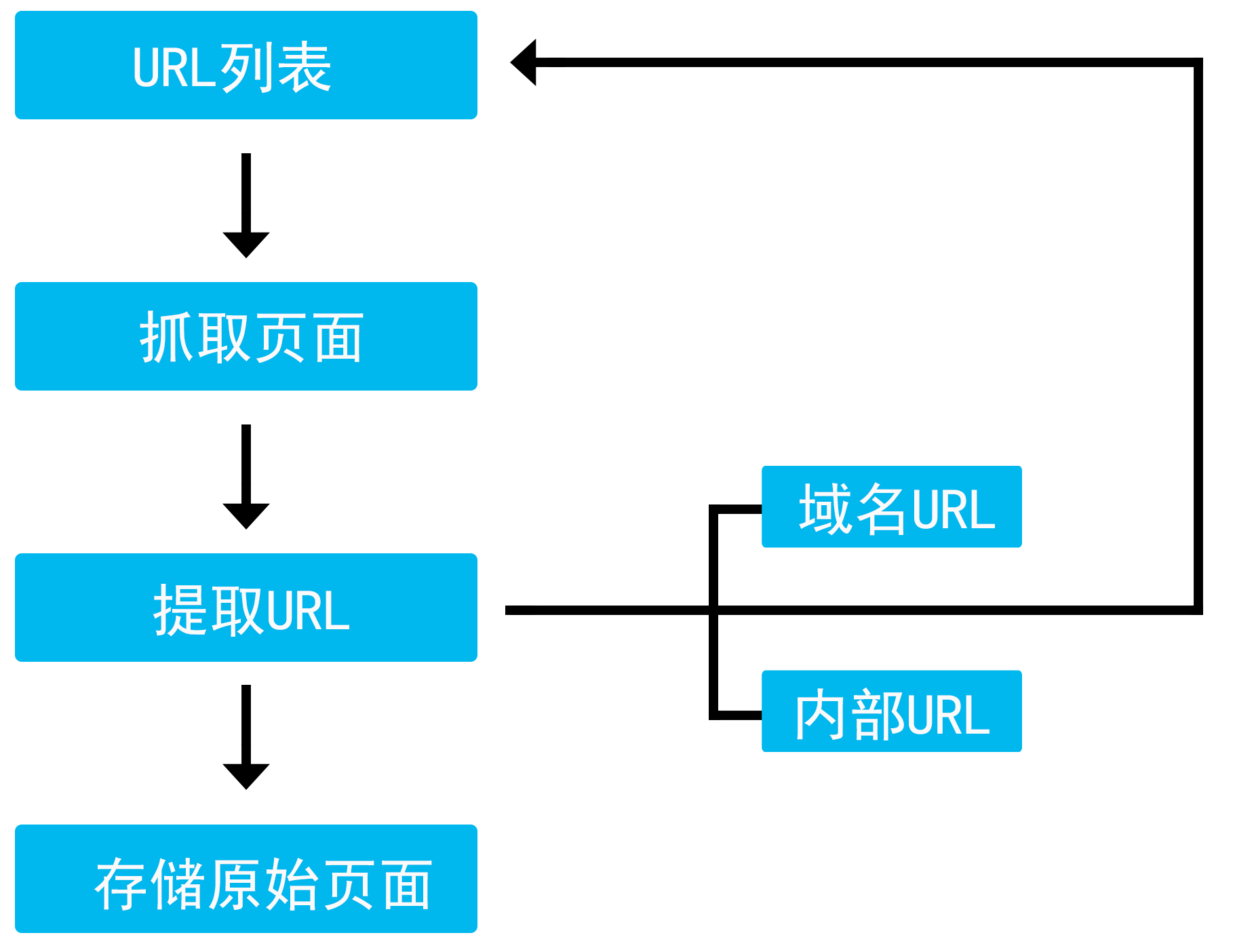
URL是页面的入口地址,域名则是整个网站的入口。搜索引擎蜘蛛程序会通过域名进入网站,然后对网站内的页面实施抓取。蜘蛛程序会从原始URL列表出发,通过URL抓取页面,然后从该页面提取新的URL存储到原始URL列表中(这个步骤会不断地重复,周而复始地累积扩大原始URL资源库),最后将该原始页面存储到搜索引擎索引库。
蜘蛛程序的执行步骤可以按照如下分拆步骤理解。
第一步:搜索引擎的爬行程序(俗称蜘蛛)发现网站,来到网站上。也就是说,网站首先要存在且能够被如蛛发现。如果网站想要被搜索引擎收录,首先网站要存在而且必须有内容。
如何让网站被搜索引擎收录呢?各大搜索引擎都提供了网页链接主动提交入口,提交网址即可(搜索引擎会判断是否收录该网站,如果不符合搜索引擎要求,即使提交了也不会收录)。提交入口在搜索引擎搜索即可。通过外链方式,在早期的优化中就有“内容为王,外链为皇”的说法,通过各种行业网站发布内容加上你的网页链接,可以通过和其他网站通过交换友情链接的方式,使搜索引擎能通过外部链接发现自己的网站,实现页面收录。
第二步:蜘蛛开始对入口页面进行抓取,并存储入口的原始页面(包括页面的抓取时间、URL、最后修改时间等)。存储原始页面的目的是为了下次比对页面是否有更新,为保证采集的资料最新,它还会回访已抓取过的网页。
第三步:提取URL。提取URL包含提取域名URL和提取内部URL。域名URL即网站首页地址,如内部URL即网站内部各页面的地址,如蜘蛛所提取的URL资源会持续添加到URL列表。
以上为搜索引擎页面抓取流程,更多请继续关注