
pyppeeteer库爬取seo文章很好用
本节内容主要是介绍用python中pyppeteer库去测试采集微信搜狗中公众号内容,用于我们日常seo素材使用。pyppeteer实际上是一个内置chrome浏览器,和selenium库相似。今天用pyppeeteer去测试采集公众号内容。
设置常规变量
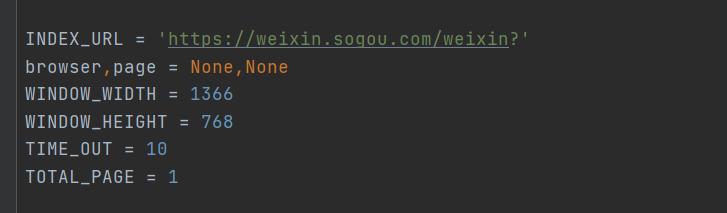
获取搜狗微信地址,浏览器对象,屏幕分辨率和超时时间,抓取页面数
创建浏览器对象
asyncdefinit():globalbrowser,pagebrowser=awaitlaunch(headless=False,ignoreHTTPSErrors=True,args=['--disable-infobars',f'--window-size={WINDOW_WIDTH},{WINDOW_HEIGHT}'])page=awaitbrowser.newPage()awaitpage.setViewport({'width':WINDOW_WIDTH,'height':WINDOW_HEIGHT})
创建浏览器对象时,设置浏览器是否为无头模式,默认True是无头模式,忽略https验证ignoreHTTPSErrors,args中一个是无痕模式,另一是设置浏览器窗口大小
抓取页面信息
比如我们抓取和'seo'相关的文章。设置参数,请求url:
asyncdefscrapy_index(page):params={'page':page,'query':'seo','type':'2'}query_string=urlencode(params)page_url=INDEX_URL+query_stringawaitscrapy_html(page_url)
asyncdefscrapy_html(url):logger.info(f'开始爬取{url}')try:awaitpage.goto(url)awaitasyncio.sleep(2)awaitpage.waitForSelector('img',options={'timeout':TIME_OUT*1000})returnTrueexceptTimeoutError:logger.error(f'请求的页面url出错{url}')
waitForSelector默认等待img元素出现,由于列表页元素和详情页元素都有共同的img元素,只要等待这个元素加载出来,页面信息就加载出来了
抓取详情页URL
asyncdefparse_page():returnawaitpage.querySelectorAllEval('.news-box.txt-boxh3a','nodes=>nodes.map(node=>node.href)')
详情页的url根据CSS选择器一步步的往下选择,返回详情页url列表。
解析详情页
asyncdefparse_detail():awaitasyncio.sleep(1)url=page.urltitle=awaitpage.querySelectorEval('h1','node=>node.innerText')author=awaitpage.querySelectorEval('#js_name','node=>node.innerText')ldate=awaitpage.querySelecotorEval('#publish_time','node=>node.innerText')try:content=awaitpage.querySelectorEval('#js_contentsection','node=>node.innerText')except:content=awaitpage.querySelectorEval('#img-content','node=>node.innerText')content='
'.join(content.split())return{'url':url,'title':title,'author':author,'ldate':ldate,'content':content}
用querySelectorEval方法获取具体数据,第一个参数是selector,获取CSS选择器,第二个是要执行的js方法。
保存数据
asyncdefsave_json(data):RESULT_DIR='results'exists(RESULT_DIR)ormakedirs(RESULT_DIR)name=data.get('title')data_path=f'{RESULT_DIR}/{name}.json'json.dump(data,open(data_path,'w',encoding='utf-8'),ensure_ascii=False,indent=2)
创建目录,并保存数据为json。
主函数运行
asyncdefmain():awaitinit()try:forpageinrange(1,TOTAL_PAGE+1):awaitscrapy_index(page)detail_urls=awaitparse_page()logger.info(f'获取详情页列表是{detail_urls}')print(detail_urls)fordetail_urlindetail_urls:flag=awaitscrapy_detail(detail_url)print(flag)ifflag:data=awaitparse_detail()awaitsave_json(data)finally:awaitbrowser.close()
调用主函数运行代码,这样就实现了微信搜狗公众号的内容的抓取了,这个库抓取数据还是挺方便的。需要源码可以关注!私信发源码。